
클로드는 왜 자꾸 멈추는가
Claude Code 를 쓰다 보면 한 가지 반복되는 패턴이 있습니다. 분명히 시킨 일이 한참 남아 있는데, 클로드가 중간에 멈춰 서서 사용자에게 “이거 어떻게 할까요” 라고 묻거나, 세션이 다시 시작되면 “지금 어디까지 했더라” 부터 다시 분석하기 시작합니다. 결과적으로 사람이 옆에 붙어 있지 않으면 일이 안 굴러갑니다.
그래서 1인 작업용 워크플로우 도구를 가볍게 만들어 써보다가, 의외로 클로드가 9,200개 정도의 태스크를 안 쉬고 돌리는 걸 봤습니다. 그러고 나서 “왜 이번엔 안 쉬었지” 를 사후에 정리해보니 두 가지 조건 같은 게 보이더라고요. 이 글은 그걸 결론 먼저 적어두고, 어쩌다 그렇게 됐는지 작업 자체의 이야기로 풀어가는 정리입니다.
본 글의 수치는 글 작성 시점에 Clawket 의 SQLite (
~/.local/share/clawket/db.sqlite) 에서 직접 뽑았습니다. by Claude 라벨이 붙은 항목은 클로드한테 SQL 이나 소스 코드 읽기를 시켜 확인한 수치입니다.
결론 먼저 — 클로드가 멈추지 않으려면 필요한 두 가지
거창한 발견을 했다기보다는 9,222개 태스크가 안 쉬고 돌아간 걸 보고 사후에 정리해본 거라, 두 조건 정도로 좁혀집니다.
첫째, 컨텍스트가 끊겨도 작업을 이어갈 수 있어야 합니다. Claude Code 의 세션은 서로 독립이라 새 세션은 빈 컨텍스트로 시작합니다 (공식 문서: “Sessions are independent. Each new session starts with a fresh context window”). TodoWrite 같은 세션 메모리는 그 시점에 비워지고, 자동 압축은 핵심 요청과 코드는 보존하지만 세부 지시는 잃을 수 있습니다. CLAUDE.md 나 외부 메모리 플러그인이 보완하긴 하지만 “방금 전까지 뭐 하고 있었지” 까지 자동으로 복원해주지는 않아서, 매 세션마다 그걸 다시 추론하는 비용이 들어가고 그 추론이 자주 어긋납니다.
둘째, 사용자에게 판단을 넘기지 않아도 되는 태스크여야 합니다. 클로드가 자율적으로 굴러가지 못하는 가장 큰 원인은 단순히 “능력 부족” 이 아니라 “이걸 어떻게 결정해야 할지 모르는 지점이 너무 자주 나오는 일을 시켰기 때문” 입니다. 결정 분기가 잦은 일은 결국 사용자에게 질문을 던지면서 멈추게 됩니다.
두 조건을 한 줄로 묶으면 이렇게 됩니다: 판단이 필요한 작업일수록 그 판단의 규칙을 미리 세워두면, LLM 이 더 많은 선택을 스스로 할 수 있게 됩니다. 그게 안 깎여 있으면 결국 사용자에게 묻게 되고, 묻는 순간 멈추는 거죠.
어쩌다 9,222 태스크가 안 쉬고 돌았나
위 두 조건은 처음부터 보였던 게 아닙니다. Clawket 이라는 1인 작업용 도구를 만들어 쓰면서 조건 ① 을 자연스럽게 풀고 있었고, 그 위에서 QA 가 필요해서 시나리오 기반 라운드 회귀를 시도해본 게 조건 ② 를 우연히 같이 푼 셈이 됐습니다. 아래는 그 두 갈래를 작업 순서대로 풀어본 정리입니다.
Clawket — 조건 ①을 푼 도구
Clawket 은 두 가지를 자동화합니다.
- 세션 시작 시 작업 컨텍스트만 자동 주입. 활성 플랜·진행 중 태스크 정도만 SessionStart 훅이 박아주고, 결정 이력이나 분석은 SQLite 안에 영구 보관해두었다가 클로드가 RAG 도구를 호출할 때만 풀(pull) 됩니다. 전체 메모리를 통째로 주입하지 않고 “지금 진행 중인 것” 만 선별 주입하는 게 claude-mem 같은 외부 메모리 플러그인과 다른 점입니다.
- 활성 태스크 없이는 코드 변경 불가. PreToolUse 훅이 Edit / Write / Bash / Agent / TeamCreate / SendMessage — 즉 코드를 바꾸거나 다른 에이전트로 위임하는 도구들 — 을 matcher 로 잡고 “먼저 태스크를 만들어 활성화하라” 는 메시지로 돌려보냅니다 (PreToolUse 의 matcher 는 도구 이름을 regex 로 잡을 수 있게 돼 있어서 표준 docs 의 예시에 안 나오는 도구도 매칭됩니다). 결과적으로 모든 파일 변경이 활성 태스크에 자동 기록되고, 에이전트 호출도 태스크에 바인딩됩니다.
그 위에 4-레이어 작업 구조를 박았습니다.
Project ── 제품 1개
│
▼
Plan ───── 산출물 본질 (사전 예비 + 라운드 내 갱신)
│
▼
Unit ───── 도메인/메뉴 그룹
│
▼
Cycle ──── 1 라운드 (실행 단계, sub-agent dispatch 단위)
│
▼
Task ───── 실행 단위 (Cycle 안에서 batch 생성, 1 Task ↔ 1 시나리오)
활성 태스크의 본문이 클로드의 작업 anchor 가 되니까, 컨텍스트가 끊겨도 같은 태스크가 다시 주입되면서 흐름이 자연스럽게 이어집니다. 조건 ① 이 풀립니다.
왜 daemon · CLI · web · plugin 으로 나눴나
Clawket 을 만들면서 가장 오래 고민한 분리입니다. 처음엔 플러그인 하나에 다 넣을까 했는데, 결국 세 가지 이유로 데몬을 따로 뽑게 됐습니다.
하나, 같은 DB 를 동시에 여럿이 들여다보고 써야 합니다. Clawket 의 SQLite 에는 같은 시점에 네 종류의 호출이 들어옵니다 — 클로드의 도구 호출마다 발화하는 훅, 사용자가 직접 치는 CLI 명령, 브라우저에 띄워둔 웹 대시보드, 그리고 클로드가 RAG 로 끌어 쓰는 MCP 서버. 호출마다 SQLite 파일을 매번 열고 닫게 두면 마이그레이션 체크 + 잠금 경합 + 파일 디스크립터 비용이 누적되는데, 훅은 도구 호출 단위로 워낙 자주 발화하기 때문에 이 비용이 빠르게 체감됩니다. 데몬이 DB 를 한 번만 열고 단일 writer 로 직렬화한 뒤 HTTP 로 모든 클라이언트를 받게 두면, 그 비용은 데몬을 한 번 띄울 때만 들어갑니다.
둘, 플러그인 폴더와 사용자 데이터의 수명이 다릅니다. Claude Code 의 /plugin install 은 플러그인 디렉토리 (~/.claude/plugins/clawket-*/) 를 통째로 삭제하고 다시 풀어내는 동작이에요. 만약 SQLite 나 캐시·설정·상태 파일을 그 안에 두면 재설치 한 번으로 작업 이력이 같이 사라집니다. 그래서 데몬은 별도 바이너리로 두고, 사용자 데이터는 운영체제 표준 위치 (XDG — ~/.local/share/clawket/ 등) 로 빼뒀습니다. 플러그인 자체는 언제든 갈아치울 수 있는 껍데기로 남고, 데이터는 그것과 무관하게 살아남습니다. 데몬은 기동 시점에 “내 데이터가 실수로 플러그인 폴더 안에 들어가 있지 않은가” 를 검사해서, 위반이 있으면 아예 기동을 거부하게 해뒀어요.
셋, 살아 있어야 하는 연결과 짧게 끝나는 호출이 한 프로세스 안에서 잘 안 어울립니다. 웹 대시보드는 서버가 보내는 이벤트 (SSE — Server-Sent Events) 를 계속 듣고 있어야 해서 연결이 길게 유지돼야 하는데, 훅 핸들러는 도구 호출당 한 번 밀리초 단위로 끝나는 단명 호출입니다. 둘을 한 프로세스 안에 욱여넣으면 어느 쪽도 깔끔하게 처리되지 않아요. 그래서 데몬이 axum (Rust HTTP 프레임워크) 위에 장수명 HTTP 서버를 들고, CLI 와 훅은 그때그때 붙었다 떨어지는 단명 클라이언트로 두는 분할이 자연스러웠습니다.
| 컴포넌트 | 역할 | 배포 형태 |
|---|---|---|
clawket (plugin shell) |
hook manifest, skills, install gate | Claude Code marketplace |
daemon (clawketd) |
axum + rusqlite + sqlite-vec, 로컬 SQLite SSoT | GitHub Releases binary |
cli (clawket) |
Rust CLI, 데몬에 HTTP 호출 + MCP stdio 서버 내장 | GitHub Releases binary |
web |
React 19 대시보드 | 정적 번들 (Cloudflare Pages) |
플러그인은 첫 SessionStart 때 GitHub Releases 에서 매칭되는 버전의 daemon · CLI · web bundle 을 받아 캐시에 풀어두고, 사용자 머신에 Rust toolchain 은 필요 없습니다.
“사전 계획 도구” 를 만들어 쓰다 — 1차 시도와 막혔던 지점
Clawket 의 초기 발상은 단순했어요. Claude Code 의 plan mode 에는 답답한 점이 있었습니다 — 결과물이 그냥 마크다운 파일이라서 새 세션이 시작되면 그건 그냥 외부 파일일 뿐, 클로드가 “지금 이 plan 안에서 작업 중” 이라는 상태를 유지해주는 게 아니었거든요. 그래서 plan 자체를 영속 엔티티로 들고 다닐 수 있게 만들자는 거였습니다. 사실상 클로드가 평소에 만드는 TODO 목록을 한 단계 위에 plan 을 두고 위계를 줘서 영속화한 거죠 — plan 의 제목·설명을 큰 task 처럼 두고 그 아래에 실제 task 들이 모이는 모양입니다.
처음 한 시도는 “이왕 영속화하니까 처음부터 모든 태스크를 사전에 다 박아두자” 였어요. 그런데 곧 막혔습니다. 실제 작업에 들어가면 (1) 미리 예측하지 못한 분기가 생기고, (2) 한 태스크를 하다 보니 다른 태스크의 모양이 바뀌어야 하고, (3) 그래서 사전에 박은 태스크의 절반쯤은 cancelled / amended 됩니다. 결국 사전에 완벽히 계획하는 건 “기존 산출물을 그대로 코드로 옮기기만 하면 되는 변환 작업” 정도가 아닌 한 거의 불가능하다는 게 분명해졌어요.
이건 새 발견이라기보다 BDUF (Big Design Up Front) 의 흔한 한계로 이미 잘 정리돼 있는 얘기입니다 — 변화가 있는 환경에서 사전 완전 명세는 “팀이 가장 적게 아는 시점에 가장 큰 commitment 를 거는 행위” 가 돼버려서, 그 commitment 가 오히려 변화 흡수를 방해한다는 거죠 (Wikipedia: Big design up front, DevIQ — BDUF antipattern).
그래서 클로드가 제안한 방식을 받아들였어요 — plan 단계에서는 도메인을 유닛 단위까지만 미리 박고, 실제 태스크는 그 유닛에 진입할 때 그 자리에서 분해해서 만든다. 사전 완전도 아니고 아예 무계획도 아닌, 중간쯤의 just-in-time decomposition 입니다.
이게 지금 Clawket 의 정본 스킬 (clawket-plan-design) 에 그대로 반영돼 있어서, plan + unit + 유닛별 시나리오 수 하한 (lower bound) 까지만 사전에 박고, 실제 task 는 라운드 활성화 시점에 clawket-verify-loop 가 서브에이전트 dispatch 로 생성합니다. 더 강하게 같은 정신을 정통화한 게 그 뒤에 분기한 SDI 인데, SDI 에서는 아예 Task 가 1등 시민이 아닙니다 — Task 는 “runtime artifact” 이고, round 가 활성화될 때 LLM 이 scenarios + requirements 에서 decompose 한다고 sdi-overview 스킬에 명시돼 있어요 (“The LLM decomposes tasks from scenarios + requirements at round activation; humans do not author tasks directly”).
QA 에 시나리오를 도입하면서 — 조건 ② 가 우연히 풀린 곳
조건 ② (사용자에게 판단을 안 넘겨도 되는 태스크) 는 Clawket 자체로는 안 풀렸어요. 그게 풀린 건 그 위에서 돌린 다른 작업 — 시나리오 기반 라운드 회귀 — 인데, 이건 처음부터 자율 루프를 의도한 게 아니라 그냥 Clawket 3.0 의 배포 전 QA 를 어떻게 할지 정리하다가 시작된 거였습니다.
당시 AWS 가 발표한 AI-DLC (AI-Driven Development Life Cycle) 의 인셉션 단계 — 요구사항을 GWT (Given/When/Then) 시나리오로 세분화해 정의하는 — 를 흉내 내서 도메인별로 시나리오를 atomic 하게 쪼개봤어요. 시나리오 하나가 task 하나에 1:1 매핑되니까 자연스럽게 태스크 수가 라운드당 수백 개 단위로 나오게 됐고, 시나리오층이 라운드 안에서 정련되며 더 늘었습니다.
QA 워크플로우 자체는 단순했습니다.
- 라운드 1 — 논리적 코드 검증. 시나리오 ↔ 코드를 논리적으로 비교 추론. 실제 기기를 두드려보지 않고 코드 흐름만 따라가서 시나리오의 Given/When/Then 이 도달 가능한지를 sub-agent 가 reasoning 합니다. evidence 필드에
file:line을 남기게 강제했고, 그게 다음 라운드의 회귀 비교 기준이 됩니다. - 시나리오가 100% 옳다고 가정하지 않습니다. 차이가 발견되면 두 갈래로 분기 — 코드가 시나리오를 못 만족시키는
defect, 또는 시나리오 자체가 두 가정이 섞이는 등 부적절한scenario_error. defect 는 별도 fix plan 의 해당 라운드 unit 으로 보내고, scenario_error 는 atomic 분해 / 의도 재정의 / 삭제 후 audit 로그에 남깁니다. - 라운드 2 이후 — 회귀 재검증. 라운드 1 에서 통과한 시나리오도 다시 평가합니다. 라운드 1 의 fix 가 통과했던 시나리오에 회귀를 일으킬 수 있기 때문에, 이전에 잘 됐다고 건너뛰지 않습니다.
- 종료 조건. 마지막 2 라운드 연속
defect=0ANDscenario_error=0. 한 라운드만 0 이어선 끝내지 않아요 — 회귀가 안 났는지 확신이 안 되니까.
여기서 한 가지는 솔직히 짚고 갈 부분이 있습니다. “이론적으로는 논리적 코드 검증으로 거의 모든 문제를 해결할 수 있지 않나” 라는 직관이 들 수 있는데, 엄밀히는 그게 그렇지 않아요. 정적 분석으로 결정 불가능한 의미적 속성이 많다는 게 Rice 정리 (Rice’s theorem) 가 1953년에 증명한 결과이고, 그래서 일반적인 정적 분석은 abstract interpretation 같은 근사로 false positive/negative 를 감수하면서 잘 동작하는 식입니다 (Alphanome — Rice’s theorem and the limits of program analysis). 우리가 한 건 그것보다 좁은 — “정해진 GWT spec 이라는 유한한 기준” 에 대해 LLM 이 reasoning 하는 — 작업이었고, 그 좁힌 범위 안에서는 휴리스틱으로 꽤 잘 동작했다는 정도가 정확한 표현이에요. “이론적으로 모든 문제를 푼다” 가 아니라 “정해진 시나리오 셋 안에서는 LLM reasoning + evidence 강제만으로도 운영 가능한 검증이 된다” 정도.
9,222 태스크가 안 쉬고 도는 걸 보고 깨달은 것
이걸 처음에는 그냥 “QA 워크플로우” 라고 부르고 있었는데, 시나리오 라운드 회귀가 7 라운드 / 9,222 태스크를 다 돌고 나서 가만 보니 깨달은 게 하나 있었어요.
처음부터 plan 의 본체로 두기에 더 자연스러운 건 “개발 설계” 가 아니라 “사용자 시나리오” 일 수도 있겠다. 이유는 두 가지인데요.
하나, 사용자 시나리오는 자연어로 적지만 GWT 라는 구조적 규칙이 있어서, 자유서술 명세보다 ambiguity 가 훨씬 적습니다. BDD 문헌에서 정리되는 ubiquitous language 의 효과가 이 부분인데, 비즈니스 / 도메인 / 구현 사이의 번역 손실을 줄이고 검증 가능한 형태로 의도를 박아두는 거죠 (Wikipedia: Behavior-driven development, CircleCI — What is BDD).
둘, 사용자 시나리오는 LLM 이 곧바로 검증 가능한 단위로 task 를 decompose 할 수 있는 형태이기도 합니다. “어떻게 만들지” 를 사전에 다 박지 않고도, “이 시나리오들을 만족하면 끝” 이라는 외부 검증 기준이 plan 시점부터 명확하게 박혀 있어요. 이게 조건 ② 를 plan 단계에서 미리 깎아두는 효과를 냈습니다 — 결정 분기마다 사용자에게 묻지 않아도, “이 시나리오를 만족하는 방향” 이라는 기준이 이미 있으니까요.
이게 SDI 의 핵심 명제와 연결됩니다 — Plan 의 1등 시민은 GWT 시나리오이고, Task 는 그 시나리오를 만족시키는 발판일 뿐이라는 모델 (sdi-overview 의 “Task is a runtime artifact, not a first-class entity”). 9,222 태스크 실험이 의도하지 않게 그 명제의 사전 증거를 깔아준 셈이 됐습니다.
운영 메커니즘 — 한 라운드 안에서 일어나는 일
위 흐름을 운영 단위로 풀면 이런 모양입니다.
Round R 시작
├─ Plan 자동 생성: "<도메인> Round R" (라운드마다 새 plan)
├─ Cycle 1 개 활성화 (cross-unit 가능)
├─ Sub-agent dispatch:
│ ├─ N agents 병렬 (1 agent / 1 unit / ≤ 30 시나리오)
│ ├─ 각 agent: scenario ↔ code reasoning (Given/When/Then 매핑)
│ └─ TSV emit: scenario_id, status, reasoning, evidence, tier_used, batch_id
├─ Bulk sync TSV → DB task status (transcription only)
├─ 수렴 판정 (3-way):
│ ├─ defect → fix plan 의 Round R unit 으로 fix task 등록
│ ├─ scenario_error → atomic 분해 / 의도 재정의 / 삭제
│ └─ 둘 다 0 + 직전 라운드도 0 → 수렴 종료
└─ /loop ScheduleWakeup → Round R+1
서브에이전트 배치 크기는 제 경험상 ≤ 30 시나리오/agent. 이건 Claude Code 의 문서화된 한계가 아니라 이 실험에서 굳어진 프로젝트 룰이에요 — 30 을 넘기는 batch 는 누락·중복 처리가 늘었고, 보수적으로 25/agent 로 잡으니 안정적이었습니다. Clawket hook 이 batch > 30 시 PreToolUse 에서 hard-fail (CLAWKET_ENFORCE_BATCH=strict default) 합니다.
세 주체의 분담은 이렇게 됐습니다.
| 주체 | 역할 |
|---|---|
| 저자 (나) | 시나리오 의도 결정, 룰 작성, 라운드 사이 결정 게이트 |
| 클로드 | 룰을 읽고 sub-agent dispatch, scenario ↔ code reasoning |
| Clawket | 영속 상태 머신 + DB + hook 강제 (scenario_id 누락 / batch > 30 / evidence 부재 차단) |
Clawket 자체가 자율 루프를 만들어준 건 아니에요. Clawket 은 작업 상태를 영속화해두는 substrate 를 제공한 거고, 시나리오 + GWT 규칙이 워크플로우의 모양을 정의했고, 그 둘이 깔린 위에서 클로드가 라운드를 굴린 거였습니다.
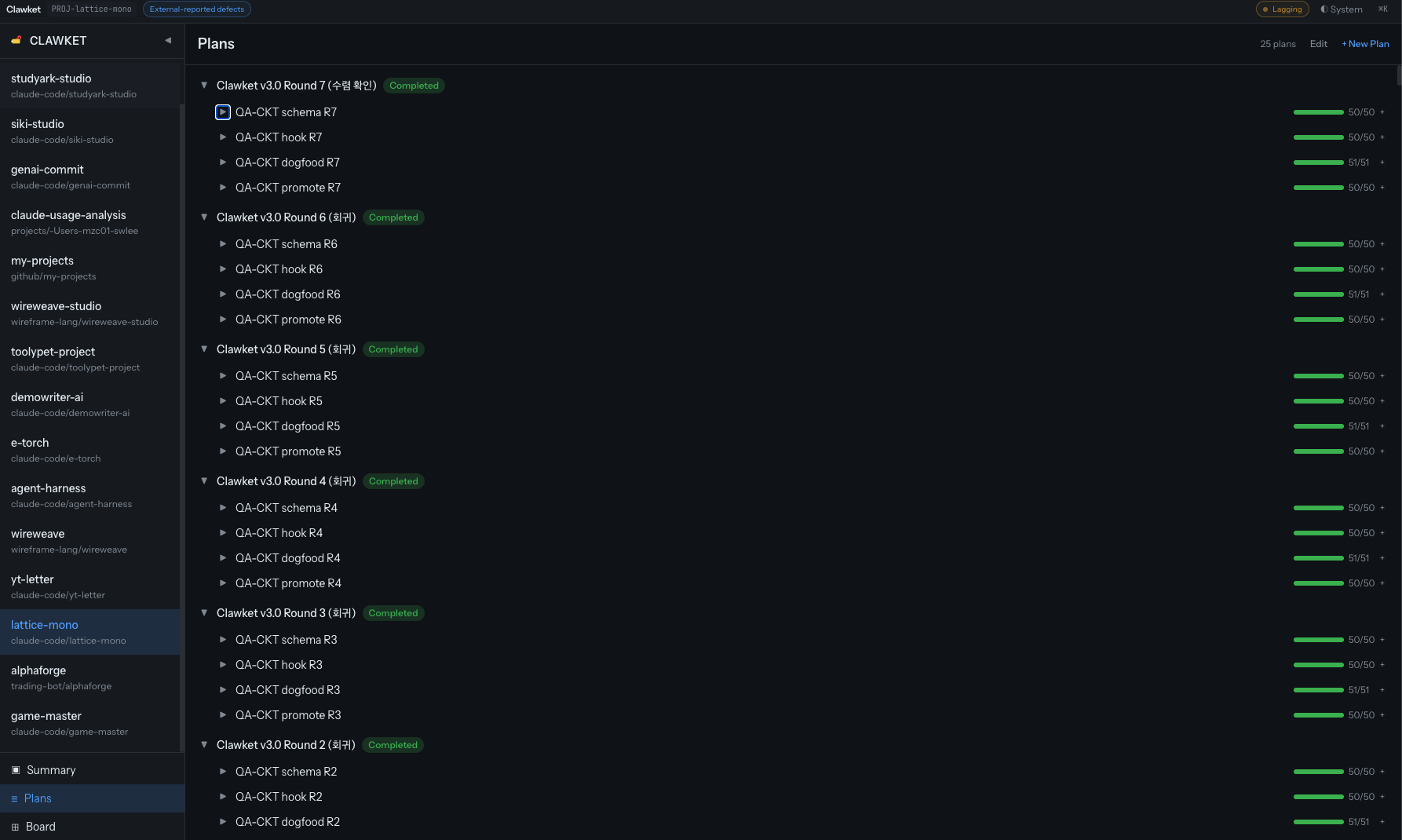
결과 — 9,222 태스크 / 7 라운드
5월 5일 자정 직후부터 태스크가 쏟아졌습니다 — 첫 태스크가 00:02 KST 에 생성됐고, 대량 생성은 01시(2,428개)와 03시(4,882개) 두 파동에 몰렸습니다 (by Claude, 시간대별 집계). 그렇게 5월 6일 오후까지 R1 ~ R7 7 라운드를 완주했습니다.
라운드별 scenario_error 정련 분포 (by Claude SQL):
| 라운드 | scenario_error | 비고 |
|---|---|---|
| R1 | 1 | atomic 분해 시작 |
| R2 | 2 | |
| R3 | 19 | 정련 피크 |
| R4 | 13 | |
| R5 | 0 | 코드층 잔여 결함 fix wave 별도 plan 처리 |
| R6 | 0 | 굳히기 1 |
| R7 | 0 | 굳히기 2 (last-2-rounds-zero 충족) |
defect 는 본 라운드 plan 이 아니라 별도 결함 해결 plan 의 라운드별 unit 에 쌓였습니다 (qa-flow.md §3 #4: “QA plan 자체는 발견 전용 — 결함 fix 는 별도 plan”). 두 plan 이 같은 라운드 키로 묶이면서 각자 수렴하는 구조입니다.
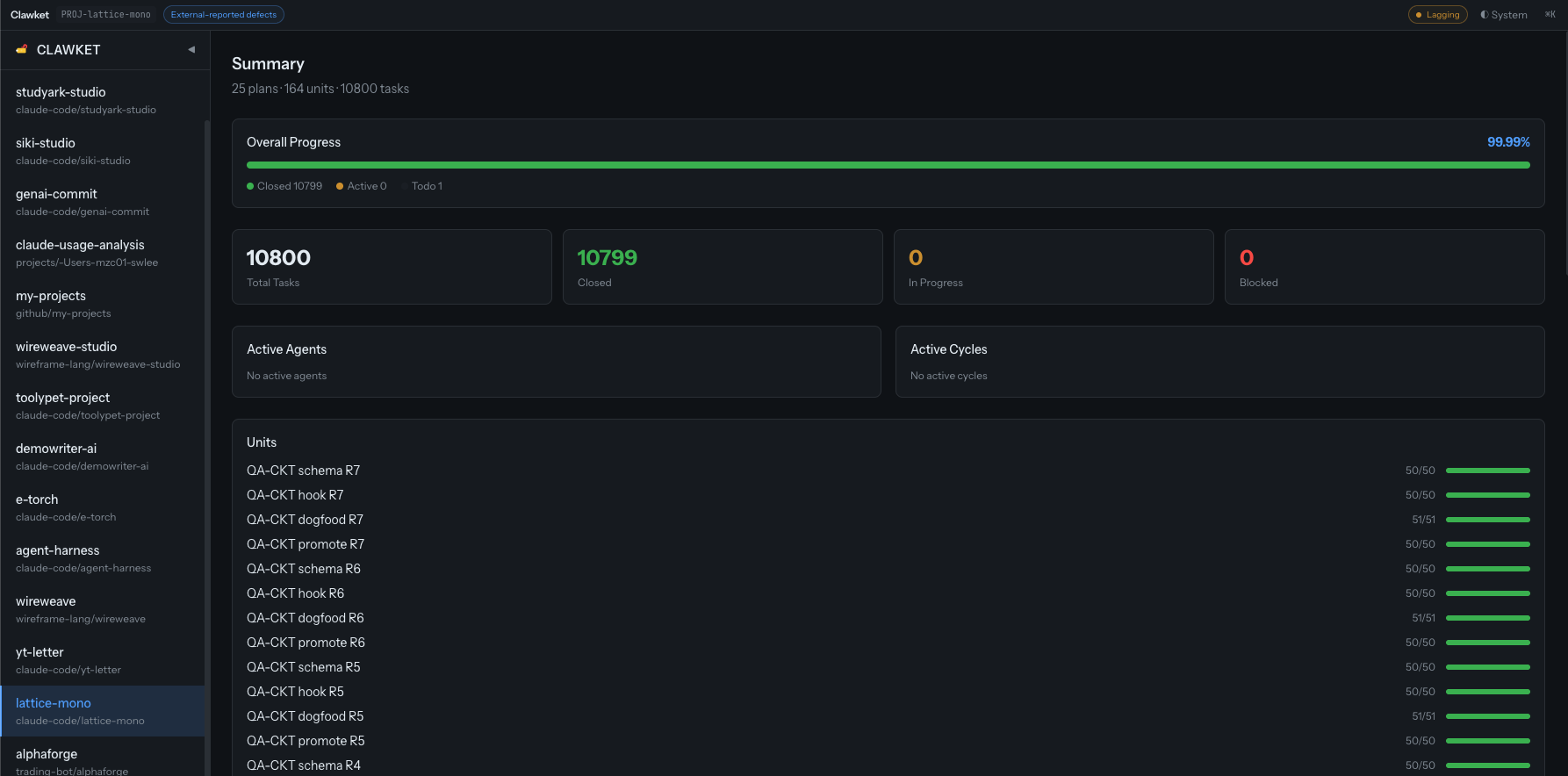
현재 DB 에 남아 있는 10,800개의 분포:
| 구간 | 기간 | 태스크 수 | 성격 |
|---|---|---|---|
| 자체 개발 | 4/14 경 시작 (조회 가능 구간 4/26 ~ 5/4) | 1,580 + α | Clawket 자체를 만드는 작업 |
| 자율 루프 | 5/5 ~ 5/6 (이틀) | 약 9,222 | 시나리오 라운드 + fix wave + 정련 |
Clawket 자체 개발은 실제로는 4월 중순(대략 4/14)부터 시작했는데, 중간에 DB 를 한 번 새로 갈아엎으면서 4/25 이전 태스크 기록이 통째로 소실됐습니다. 그래서 위 표의 자체 개발 1,580개는 살아남은 4/26 이후 구간만 센 값이고, 초기 구간이 몇 개였는지는 지금은 조회할 수 없습니다. 표의 10,800 역시 그 소실분이 빠진 “현재 DB 에 남은” 수라는 점을 감안하고 보면 됩니다.
본문 도입의 “약 9,200” 은 위 표의 9,222 를 가리킵니다. 5월 5일 하루에만 8,401개의 태스크가 생성됐습니다 (by Claude, SELECT COUNT(*) FROM tasks WHERE date(created_at/1000, 'unixepoch','+09:00') = '2026-05-05').
자율 루프가 굴러가는 동안 분당 100건 이상의 status 변경이 일어난 분이 5/5 ~ 5/6 동안 총 19분, 누적 11,943건 발생했습니다 (by Claude, activity_log 분당 집계 SQL). Peak 는 5월 5일 01:59 KST 의 2,318 건/분. sub-agent batch reasoning 이 끝나고 TSV → DB 1:1 옮기는 동기화 전사(transcription) 단계라 분당 1,000+ 도 정상 범위이고, 이 단계가 안정적으로 작동했다는 흔적이기도 합니다.
한 갈래에서 두 갈래로 — Clawket 3.x 강화 + SDI 분기
이 실험은 결과적으로 두 갈래의 작업을 만들었습니다.
한 갈래는 Clawket 안쪽으로 들어갔습니다. 자율 루프에서 검증된 패턴 — 라운드별 새 Plan, 시나리오 1:1 태스크 매핑, 서브에이전트 batch dispatch + 7필드 TSV evidence + 3-way 수렴 판정 — 을 Clawket v3.x 의 정본 스킬로 흡수했습니다.
/clawket-plan-design— Plan + Unit 사전 예비 설계/clawket-scenario-author— atomic 시나리오 작성 (Given/When/Then)/clawket-verify-loop— 라운드 종단 실행 + 3-way 수렴 판정/clawket-verify-batch— sub-agent batch dispatch + 16-worker ThreadPoolExecutor bulk sync/clawket-scenario-refine— scenario_error 처리 (atomic 분해/의도 재정의/삭제)/clawket-defect-fix— defect 행 → fix task 등록
이 스킬들이 5월 5일 Clawket v3.0.0 의 정본 스킬로 묶였고, 5월 19일 v3.1.0 에서 clawket-* 프리픽스 정본화를 거쳐 5월 24일 v3.1.6 까지 점진적으로 다듬어지고 있습니다.
다른 한 갈래는 별도 도구로 분기했습니다. 9,222 태스크 실험에서 얻은 통찰을 그대로 Clawket v4 로 넣지 않고, 별도 새 도구를 새 org 에서 짓기로 했습니다. 이름은 SDI (Scenario-Driven Implementation), org 는 @scenario-driven 입니다.
분기 이유는 단순합니다. Clawket 은 이미 “활성 태스크 없이는 코드 변경 불가” 라는 자기 정체성을 가진 도구입니다. SDI 가 던지려는 명제는 다릅니다 — 시나리오(Given/When/Then)가 1등 시민이고, Task 는 시나리오를 만족시키는 발판 이라는 모델입니다. 둘은 양립할 수 있지만, 같은 도구 안에 두면 어느 한쪽의 정체성이 흐려집니다. 그래서 Clawket 은 Clawket 의 정체성으로 계속 강화하고, SDI 는 별도로 짓는 쪽을 선택했습니다.
도메인 매핑은 이렇게 됩니다 (정본 출처: sdi-plugin/docs/MIGRATION-clawket-to-sdi.md).
| Clawket v3 | SDI | 성격 |
|---|---|---|
Plan |
Plan |
그대로 계승 |
Unit |
Scenario.tag |
강등 — 엔티티 → 태그 |
Cycle |
Round |
재의미화 — WIP 경계 → 회귀 wave |
Task |
Task |
같은 lifecycle, 그러나 1등 산출물 아님 |
type=decision artifact |
Decision |
승격 — 1등 엔티티 |
--evidence "string" |
구조화 evidence | free string 거부 |
| (ad-hoc) | Requirement |
신규 — snapshot-only |
위 표에서 한 줄로만 적은 항목 둘은, 앞에서 손으로 굴린 검증 규칙이 데이터층 계약으로 굳은 경우입니다. 라운드 검증 때 evidence 에 file:line 을 남기게 한 건 그때는 그냥 컨벤션이었는데, SDI 에서는 자유 문자열 evidence 를 아예 거부하고 각 Task 의 done 이 {scenario_id, status: pass|fail, ref}[] 구조화 evidence 를 들도록 데이터층에서 강제합니다 (MIGRATION 의 “free string rejected” 행). 또 Requirement 는 현재 상태(snapshot)만, Decision 은 history(append-only)만 담도록 분리해서, Requirement 본문에 변경 이력이 섞여 들어오면 MOVE_TO_DECISION 으로 거부됩니다. 둘 다 이 글이 말하는 “결정 규칙을 구조로 박는다” 가 데이터 스키마 레벨까지 내려간 사례예요.
SDI 가 신규로 들고 가는 것은 GWT 시나리오 1등 시민, Requirement / Decision 엔티티, 멀티에이전트(M1–M5) · CollaborationPattern 등입니다. 마지막 멀티에이전트 부분은 5월 후반에 작업이 본격화됐고, 그 이야기는 다음 글에서 다루려고 합니다.
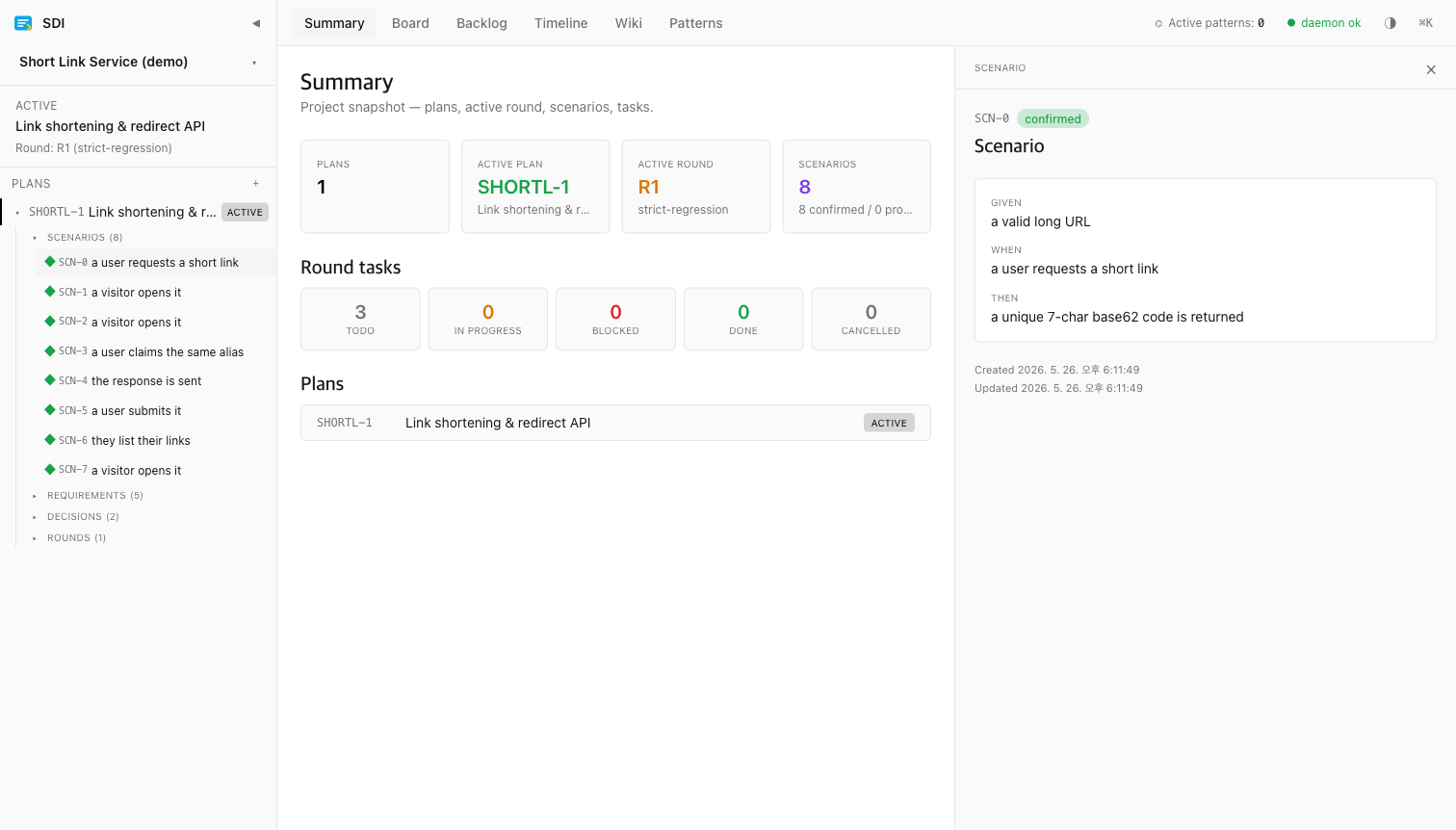
대시보드를 띄우면 위 표의 모양이 그대로 보입니다. 사이드바에 Plan 아래로 Scenarios / Requirements / Decisions / Rounds 가 1등 엔티티로 펼쳐지고, Task 는 그 자리에 없습니다. 시나리오를 열면 Given/When/Then 이 그대로 나오는데, 회사 식별자가 박힌 실데이터를 그대로 첨부할 수 없어 동일 스키마로 깨끗한 데모 plan 을 따로 시드해서 캡처한 화면이에요.
패턴 — “결정 표면을 미리 깎는다”
다시 처음의 두 조건으로 돌아가면, 이 실험에서 굳어진 패턴은 한 줄로 요약됩니다.
클로드를 오래 굴리는 방법은 클로드를 똑똑하게 만드는 게 아니라, 결정해야 할 표면을 미리 깎아두는 것이다.
조건 ① (컨텍스트 지속) 은 도구가 풀어줍니다 — 활성 태스크를 자동 주입하는 SessionStart 훅 같은 것. 조건 ② (판단 위임 최소화) 는 워크플로우가 풀어줍니다 — 시나리오 기반 라운드 회귀처럼 결정 분기를 룰로 미리 박아두는 것. 두 조건이 동시에 풀려야 자율 루프가 굴러갑니다. 조건 ② 를 SDI 에서는 AutonomyPolicy(스코프별 자율 수준)와 consensus/dissensus 게이트라는 1등 엔티티로 형식화했는데, 그 본론은 멀티에이전트를 다루는 다음 글로 미뤄둡니다.
복잡한 태스크는 단순히 복잡한 채로 두면 안 되고, 명확한 규칙으로 단순 반복 태스크처럼 모양을 바꿔야 합니다. 그게 안 되는 일이라면 그 일은 애초에 자율 루프 후보가 아닙니다.
여러분도 클로드를 오래 굴리려면 도구만 바꿀 게 아니라 일의 모양 자체를 바꿔보는 건 어떨까요. 막상 해보면 “AI 가 멈추는 지점” 이 사실은 “내가 결정 규칙을 미리 만들지 않은 지점” 인 경우가 의외로 많습니다.